CloudTrail のログを Kibana で可視化して改善のヒントを探す
Posted on
- #aws
7 月から東京リージョンでも使えるようになった CloudTrail(一部のサービスはまだ未対応)。 API 呼び出しのすべてが記録されるのでセキュリティ監査の証跡ログとして利用されることが多いと思います。
オンプレミスで同じことをやろうとするとコストも労力も馬鹿になりませんが、CloudTrail ならポチッと有効にするだけです。素晴らしいですね!
セキュリティ監査の証跡ログだけではもったいないので、他の活用方法を考えてみました。
CloudTrail のログをどう活用するか
CloudTrail のログには AWS CLI / SDK からのリクエストはもちろんのこと、Management Console の操作も記録されています。 Management Console も裏側で API を叩いているからです。
API を使って構築や運用の自動化を進めると Management Console で作業する回数は減っていくはずです。 Management Console での作業が多く記録されていれば、その作業を自動化すれば効率が上がるかもしれません。
今回は Management Console で作業した内容を可視化して、改善のヒントを探してみます。
Elasticsearch と Kibana をインストールする
CloudTrail のログは JSON 形式です。
15 分おきに gzip で固められ、指定した S3 バケットに保存されます。 JSON が扱えて可視化が得意といえば Elasticsearch と Kibana の組み合わせしかありません。
EC2 に必要なミドルウェアをサクッとインストールします。今回は t2.micro を使いました。
まずは Elasticsearch をインストールします。公式の RPM パッケージが用意されています。
$ sudo rpm -ivh https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.3.2.noarch.rpm
$ sudo chkconfig --add elasticsearch
$ sudo service elasticsearch start
localhost の 9200 番ポートにリクエストを投げて JSON が返ってくれば OK です。
$ curl -X GET http://localhost:9200/
{
"status" : 200,
"name" : "Sergeant Fury",
"version" : {
"number" : "1.3.2",
"build_hash" : "dee175dbe2f254f3f26992f5d7591939aaefd12f",
"build_timestamp" : "2014-08-13T14:29:30Z",
"build_snapshot" : false,
"lucene_version" : "4.9"
},
"tagline" : "You Know, for Search"
}
次に Kibana です。 Kibana はクライアントサイドで処理されるので、スタティックなファイルのみで構成されています。なので、Web サーバのドキュメントルートにファイルを置くだけです。
データの取得は Ajax で Elasticsearch に検索クエリを投げています。
$ sudo yum install httpd
$ sudo chkconfig httpd on
$ sudo service httpd start
$ wget https://download.elasticsearch.org/kibana/kibana/kibana-3.1.0.zip
$ unzip kibana-3.1.0.zip
$ sudo mv kibana-3.1.0/ /var/www/html/kibana/
最後に Security Group で 80 番と 9200 番のポートを開きます。 9200 番は Kibana が検索クエリを投げるポートです。
ミドルウェアのセットアップはこれで終わりです。 "http://(Public DNS)/kibana/" で Kibana の画面が見れるはずです。
CloudTrail のログをインポートする
CloudTrail のログを Elasticsearch にインポートしていきます。
まず S3 にある CloudTrail のログを先ほど立ち上げた EC2 にコピーします。 AWS CLI を使って丸ごとコピーするのが簡単です。
$ mkdir cloudtail
$ cd cloudtrail/
$ export AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxxxxxxxx
$ export AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
$ export BUCKET_NAME=xxxxxxxx
$ export ACCOUNT_ID=xxxxxxxxxxxx
$ aws s3 cp --recursive s3://${BUCKET_NAME}/AWSLogs/${ACCOUNT_ID}/CloudTrail/ .
Elasticsearch には Bulk API が用意されており、JSON を高速にインポートすることができます。ですが、CloudTrail のログは 15 分おきにファイルが作られるため Bulk API を使うにはファイルをマージする必要があります。
今回はデータ量がそれほど多くないので、スクリプトで 1 件ずつインポートします。次のスクリプトを import-cloudtrail-log.sh として保存して実行してください。
#/bin/bash
for file in `find -type f -name *.json.gz -size +0c`; do
length=`zcat ${file} | jq '.Records | length'`
index=`expr ${length} - 1`
for i in `seq 0 ${index}`; do
log=`zcat ${file} | jq -c ".Records[${i}] | select(.userAgent==\"console.amazonaws.com\") | {eventTime: .eventTime, eventName: .eventName}"`
if [ ! -z ${log} ]; then
curl -s -X POST 'http://localhost:9200/cloudtrail/log/' -d ${log} > /dev/null
fi
done
done
このスクリプトでやっていることは、
- JSON の Records オブジェクトをループで回して、
- userAgent が console.amazonaws.com にマッチするものだけ選び、
- eventTime と eventName のオブジェクトを作って、
- Elasticsearch にインポートする
eventTime と eventName 以外のデータを省いているのは、データ量を減らしたかったのと、accessKeyId などセンシティブなデータはインポートしたくないからです。
Kibana で可視化する
データがインポートできたので可視化してみましょう。
- Kibana のトップページから Blank Dashboard を選択
- 右下の Add a row を選択
- Title を入力して Create Row、次に Save を選択
- Add panel to empty row を選択
- 以下の画像を参考に pie のグラフを追加
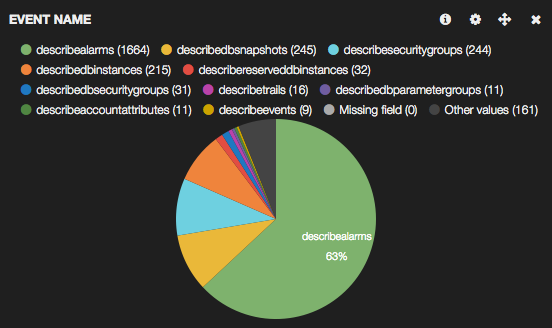
自分のアカウントのログを可視化するとこんな感じになりました。 CloudWatch の DescribeAlarms が圧倒的に多いですが、おそらく EC2 インスタンスの一覧画面を表示した際に裏でチェックしているためです。
まとめ
CloudTrail のサードパーティー製品を使わなくても、Elasticsearch と Kibana で簡単に可視化できました。自分のログだと describe 系が上位を占めてしまい改善のヒントは得られませんでしたが、もう少し工夫すれば別の観点で気づきが得られそうです。
ログは溜めていても 1 円も価値を生み出しません。 AWS ならストレージの運用コストがゼロになるので、浮いた時間でログから価値を見出すことに力を入れたいと思います。
それでは、よい AWS ライフを!