Amazon Athena で CloudFront のログを分析してみる
Posted on
AWS re:Invent 2016 で発表された Amazon Athena はすごく盛り上がっていますね。 S3 にあるファイルに対してアドホックにクエリを実行できるので、これまで EMR でやっていた集計処理を Athena に置き換えられそうです。
仕事でもさっそく使っていこうと思っていますが、まずは手始めにこのブログの CloudFront のログを分析してみました。
データベースとテーブルを作る
Catalog Manager というウィザード形式で作ることもできますが、SQL のほうが楽なので Query Editor から DDL を発行します。
CloudFront のログを集計するためのデータベースを作ります。
CREATE DATABASE cloudfront_logs;
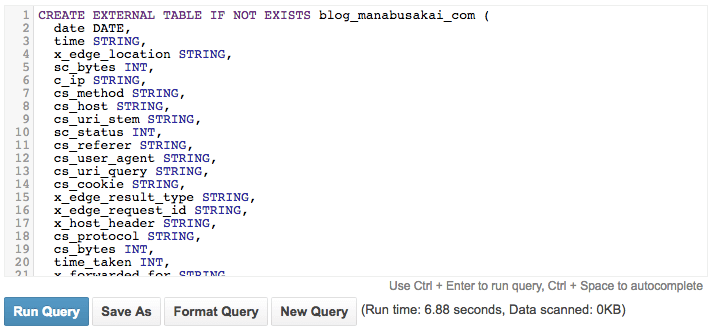
続いてテーブルを作ります。 CloudFront のログはタブ区切りの TSV 形式で、フィールドは全部で 24 個あります。
TSV のフィールド名を小文字のアンダースコア区切りにして、テーブルのカラム名にしました。
CREATE EXTERNAL TABLE IF NOT EXISTS blog_manabusakai_com (
date DATE,
time STRING,
x_edge_location STRING,
sc_bytes INT,
c_ip STRING,
cs_method STRING,
cs_host STRING,
cs_uri_stem STRING,
sc_status INT,
cs_referer STRING,
cs_user_agent STRING,
cs_uri_query STRING,
cs_cookie STRING,
x_edge_result_type STRING,
x_edge_request_id STRING,
x_host_header STRING,
cs_protocol STRING,
cs_bytes INT,
time_taken INT,
x_forwarded_for STRING,
ssl_protocol STRING,
ssl_cipher STRING,
x_edge_response_result_type STRING,
cs_protocol_version STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ' ', -- タブ文字 (\t)
'field.delim' = ' ' -- タブ文字 (\t)
)
LOCATION 's3://cloudfront-xxxxxxxxxxxx/blog.manabusakai.com/'
;
最後の LOCATION で指定しているのが CloudFront のログです。ここに約 3 か月分のログが入っており、gz 形式で約 35 MB でした。
SQL が成功すると、左のナビゲーションにテーブルとカラムが表示されます。
HTTP/2 のサポート状況を調べてみる
CloudFront の管理画面にある Reports & Analytics ページでは見れない HTTP/2 のサポート状況を調べてみました。分析の SQL はこんな感じです。
SELECT
cs_protocol_version,
COUNT(*) AS count
FROM
blog_manabusakai_com
WHERE
cs_protocol_version IS NOT NULL
GROUP BY
cs_protocol_version
ORDER BY
count DESC
;
結果はこうなりました。技術ブログというジャンルのせいか、全リクエストの 46 % が HTTP/2.0 で接続していることがわかりました!

今回はログの量も大したことがないので全件に対してクエリを実行していますが、本番環境で実行するときは注意しましょう。 Athena はスキャンしたデータ量によって課金されます。公式ブログには次のように書かれています。
各クエリでどれだけのデータがスキャンされたか(クエリ実行後にコンソールに表示されます)を基準に課金されます。これが意味するところとして、圧縮やパーティション、またはデータを列指向のフォーマットに変換することで、格段にコストを抑えられることがおわかりかと思います。
まとめ
Athena を使えば S3 にあるログを手軽に分析できることがわかりました。 EMR も使ったことがありますが、Athena のほうが圧倒的に簡単です。 Athena は Presto をベースにしているので、これまで EMR で培ったノウハウも活かせそうです。
ログ分析のために BigQuery を使っていた人にとっても Athena は魅力的ではないでしょうか。
また本番環境のログで試してみて、ノウハウが貯まってきたら改めて書こうと思います。